
一个项目,需要维护崂山区的小区建成年代信息。相关部门给的数据并不全,自己去找这些数据也比较麻烦,后来发现安居客有相关的信息,于是想着爬取一下。
黑客程序媛 / 逆向工程师 / 人工智能学徒 / 用爱发电的独立开发者
一个项目,需要维护崂山区的小区建成年代信息。相关部门给的数据并不全,自己去找这些数据也比较麻烦,后来发现安居客有相关的信息,于是想着爬取一下。

github在为支持私有项目之前,很多的代码都是基于bitbucket托管的。整体体验也还算ok。不过有段时间bitbucket服务貌似周期性被墙,尤其是登录跳转,异常的恶心。在bitbucket上托管的代码基本都是非公开的项目,包含各种图片站的爬虫,语音助理等。
Bitbucket 对于个人以及最多具有 5 位用户的小型团队是免费的,并提供无限制的公共和私人存储库。您还可以获得 LFS 的 1 GB 文件存储和 50 分钟的构建时间,以便开始使用 Pipelines。您可以在工作区与所有用户共享构建分钟数和存储。

网上搜一下,读取cookie的基本都是这份代码。我也忘了是从那里抄来的了,这里贴一下 ,对于最新的chrome需要修改下路径:
# chrome 96 版本以下 # filename = os.path.join(os.environ['USERPROFILE'], r'AppData\Local\Google\Chrome\User Data\default\Cookies') # chrome96 版本以上 # filename = os.path.join(os.environ['USERPROFILE'], r'AppData\Local\Google\Chrome\User Data\default\Network\Cookies')
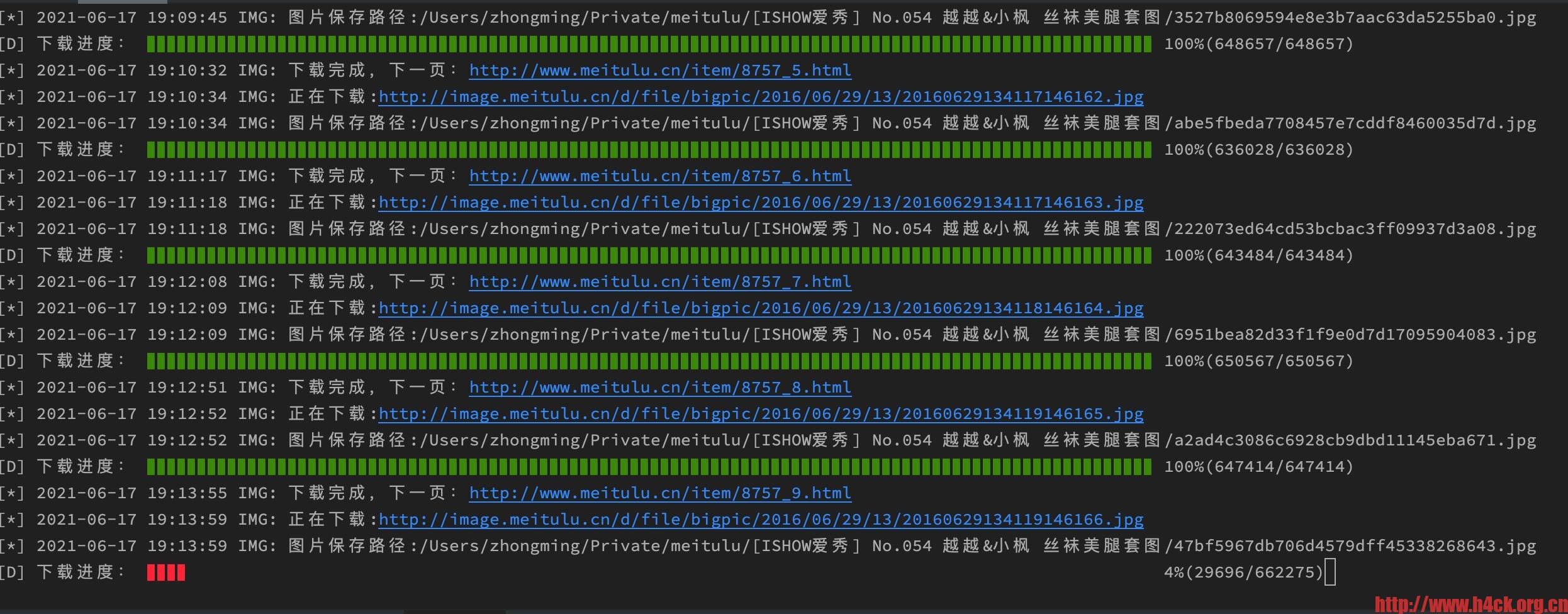
代码:
def proxy_get_content_stream(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
return requests.get(url, headers=HEADERS, stream=True, timeout=300)
def save_image_from_url_with_progress(url, cnt):
with closing(proxy_get_content_stream(url)) as response:
chunk_size = 1024 # 单次请求最大值
content_size = int(response.headers['content-length']) # 内容体总大小
data_count = 0
with open(cnt, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
data_count = data_count + len(data)
now_position = (data_count / content_size) * 100
print("\r[D] 下载进度: %s %d%%(%d/%d)" % (int(now_position) * '▊' + (100 - int(now_position)) * ' ',
now_position,
data_count,
content_size,), end=" ")
print('')
BeautifulSoup4解析页面的时候发现有一部分内容是乱码,刚开始还以为是pycharm的问题,后来发现可能问题不是出在pycharm上,因为普通的print打印的中文是没有问题的。测试代码如下:
def proxy_get(url):
if is_use_proxy:
socks.set_default_proxy(socks.SOCKS5, PROXY_HOST, PROXY_PORT)
socket.socket = socks.socksocket
req = requests.get(url, headers=HEADERS)
return req.text
def get_sub_pages_test(url):
'''
http://www.meitulu.cn/t/shishen/
:param url:
:return:
'''
bs = BeautifulSoup(proxy_get(url), "html.parser")
boxes = bs.find('div', class_='boxs')
lis = boxes.find_all('li')
log_text('PAGE', '开始分析页面链接', is_begin=True)
for l in lis:
p = l.find('p', class_='p_title')
print( p.text)
当你在凝视深渊的时候,深渊也在凝视着你 -- 尼采《善恶的彼岸》
什么是网络色情?严谨的定义就是:凡是网络上以性或人体裸露为主要诉求的讯息,其目的在于挑逗引发使用者的性欲,表现方式可以是透过文字、声音、影像、图片、漫画等。
互联网萌芽年代 邮件传输——当时在大学科研院所以及一些公司,已经有人通过软盘、邮件来传输一些来自台湾、日本的纯色情文字。
互联网普及年代 搜索引擎之SEX和XXX搜索——有了搜索引擎,给网络色情的中国的发展带了巨大的发展。96年的YAHOO,97年国内的SOHOO,其搜索结构中,SEX和XXX主体字的搜索占了很大的比例。
互联网发展年代 个人主页、情色电影、明星图片、性爱课堂、色情文学
个人网站初期,色情的躲避和小范围传播:98年,国内的碧海银沙和网易推出了免费申请的个人主页空间,网络用户大量增加。当时的政策是,一旦发现某个个人网站中有色情成分,如果被空间提供商发现,就会停止器个人空间,如果被公安局发现,就会连带影响到整台服务器。 门户网站的边缘内容从情色电影、明星图片到性爱课堂:99年国内开始出现门户的概念,以大内容吸引更多网民访问的网站,已经主动提供了一些可算可不算色情的内容,比如提供情色电影海报,介绍等,特别是各种明星图片。